
Review of Voice-to-Text Converter
- Dragon Anywhere
| Pros | Cons |
| Precise transcription | Expensive compared to competitors |
| Export documents to other platforms | Needs internet connection |
| Voice commands for hands-free operation | Subscription-based pricing model |
| Tailored to meet individual preferences | Limited free trial period for new users |
| Works offline, thereby increasing flexibility | Advanced features may not be needed for all users |
What is Dragon Anywhere?
Nuance offers a mobile app for its Dragon speech-to-text software called Dragon Anywhere, available on Android and iOS for users in the United States and Canada.
Dragon Anywhere, a professional-grade mobile dictation app, makes it easy to create, edit, format, and share documents of any length directly from your mobile device, whether you’re visiting clients, on a job site, or at your local coffee shop.
The Dragon Anywhere mobile app functions similarly to the cloud-based version but is designed for use on a mobile phone. It allows you to dictate words and convert them into text with high accuracy, with no time limits on transcription, enabling you to speak as long as you need. Like the desktop app, you can add custom words and edit your transcribed documents within the app for precision. You can then export your documents to cloud-based storage platforms like Dropbox and Google Drive.
The mobile app is available for $15 per month or at a discounted rate of $150 for an annual subscription. Enterprises with multiple users can contact Nuance’s sales team to negotiate discounted volume licenses.
Who uses Dragon Anywhere?
Dragon Anywhere, a professional-grade mobile dictation app, enables users to effortlessly create, edit, format, and share documents of any length directly from their mobile devices.
Modern smartphones and tablets can perform nearly all the tasks a desktop or laptop can, with one exception: providing a comfortable way to write and edit lengthy documents. Dragon Anywhere, a top-tier speech-to-text app for Android and iOS devices, addresses this gap with high accuracy and advanced voice recognition technology that adapts to a user’s voice over time.
In this review, we thoroughly tested Dragon Anywhere, Dragon’s premier mobile speech recognition solution. With features like multi-format document support, it proves to be a convenient speech-to-text tool. However, it also has some notable shortcomings.
Specifications
Since Dragon Anywhere is a cloud-based voice recognition service, an active internet connection is required to use it.
| Feature | Description |
| Continuous dictation | Speak continuously, and Dragon Anywhere will transcribe your words with precision. |
| No word limits | Dictate documents of any length without worrying about a word limit. |
| 99% accuracy | Dragon Anywhere’s advanced speech recognition engine ensures 99% accuracy, even in noisy environments. |
| Voice formatting and editing | Use your voice to format text, select and edit words and sentences, delete content, and more. |
| Auto-text | With just a few spoken words, create and insert custom text passages, such as client descriptions or work orders. |
| Cloud integration | Import and export documents to and from popular cloud-sharing tools like Dropbox® and note-taking apps like Evernote. |
Features
Dragon Anywhere allows users to dictate lengthy documents without any restrictions on dictation time or page numbers. Mistakes made during dictation can be easily corrected using simple voice commands like “correct that.” This command opens a correction menu that provides a contextual list of alternative phrases to choose from.
Dragon Anywhere allows users to dictate lengthy documents without any limitations on the number of pages or dictation time. If an error occurs during dictation, users can correct or modify a previous sentence by simply saying “Correct that.” This command brings up a correction menu with a list of contextually appropriate alternative phrases.
Other typing programs often struggle with recognizing unusual words or names, which can be frustrating when writing on specialized topics. Dragon Anywhere addresses this issue with its Train Words tool, enabling users to quickly teach the app how to spell and pronounce non-standard words or phrases.
Once a document is completed in Dragon Anywhere, it can be sent as an email or exported in various formats. Files are automatically synced across all Dragon-enabled devices if you use a compatible desktop app. Additionally, Dragon Anywhere can integrate with third-party platforms like Dropbox and Evernote.
Set up
Getting started with Dragon Anywhere is a breeze. Simply download the app from the Google Play Store or iOS App Store, register for a Dragon account, and choose a subscription option. Following that, a brief tutorial video will guide you through the Dragon Anywhere interface. During our trial on a Google Pixel 2, we encountered an issue where the tutorial video failed to load properly. However, this was easily resolved by finding a similar walkthrough clip online.
To complete the setup process for Dragon Anywhere, familiarize yourself with the phrases for making corrections during dictation. Additionally, it’s essential to train the app to recognize uncommon keywords by using the Add Word feature to type and record the unusual word or phrase.
Starting with Dragon Anywhere is straightforward. Simply download the app from either the Google Play Store or the Apple App Store, then register for a Dragon account and select a subscription plan. Once done, a brief tutorial video will guide you through the Dragon Anywhere interface. During our testing on a Google Pixel 2, we encountered difficulties loading the tutorial video, but this was easily overcome by finding a comparable video tour online.
Familiarize yourself with the phrases used for making modifications during dictation, and ensure the program recognizes unusual keyword combinations. To do this, use the “Add term” feature, type in and record the unique term or phrase, and then select “Done.”
Interface
The user interface of Dragon Anywhere may not be particularly flashy. Across the top edge of most screens within the app, you’ll find permanent shortcuts for downloading, uploading, deleting, and creating new documents. Additionally, a contextual help icon may appear as needed. In the Documents view, you’ll see a basic list of previous transcriptions that can be opened for editing or exporting.
However, the most crucial aspect of the Dragon Anywhere interface is the dictation screen. Here, you’ll encounter a prominent microphone icon that you can tap to initiate speech input. If you make an error, correcting it is simple using one of Dragon’s text commands. The contextual editing menu functions smoothly, presenting a numbered list of alternative phrases for you to select from verbally.
The user interface of Dragon Anywhere isn’t particularly captivating, Across most screens in the app, you’ll find fixed shortcuts along the top edge for functions like downloading, uploading, deleting, and starting a new document. Often, a contextual help icon will also be visible. In the Documents view, a simple list of previous transcriptions is available, which can be opened for editing or exporting.
However, the dictation screen is undoubtedly the focal point of the Dragon Anywhere user experience. Here, a large microphone symbol awaits your tap to initiate speech input. If errors occur, correcting them is straightforward using one of Dragon’s text commands. The contextual editing menu functions smoothly, providing a selection of alternative phrases to choose from.
Performance
We found Dragon Anywhere to be an exceptionally reliable voice-to-text app, particularly as it adapted to our voice over the review period. Occasionally, the app struggled with tricky words when using a Bluetooth headset, but accuracy remained high when we used our phone’s built-in microphone. However, one performance issue that may frustrate many users is that Dragon Anywhere relies solely on cloud computing. This means that without a WiFi or mobile data connection, the app will not function at all.
Accuracy
Dragon Anywhere’s use of Dragon’s renowned software to convert spoken words into text results in exceptional accuracy, which is one of its strongest features. Most users rate Dragon Anywhere’s accuracy at around 90%, and my experience was similar, though it wasn’t perfect. The application quickly transcribed a variety of test paragraphs, making it easy for me to maintain my writing flow. Overall, it performs better in terms of speed and precision compared to the built-in tools in Word and Google.
However, be aware that your environment can impact performance. I used Dragon Anywhere in a moderately quiet room while speaking clearly. Ambient noise and distortion can degrade quality if you’re on the move while dictating. Additionally, I found that outlining your work beforehand helps ensure clearer pronunciation, which improves accuracy.
Set up
Getting started with Dragon Anywhere is simple. After downloading the app from either the Google Play Store or the Apple App Store, register for a Dragon account and choose a subscription plan. Then, a brief tutorial video will guide you through the Dragon Anywhere interface. During our testing on a Google Pixel 2, we encountered issues with the tutorial video not loading properly.
To complete the setup, familiarize yourself with the phrases used for making modifications during dictation. Another crucial step is teaching the program to recognize unusual keyword combinations. To do this, select the “Add term” button, type in and record the unique term or phrase, and then select “Done.”
Support
The majority of technical inquiries about problems with the Dragon Anywhere app can be resolved by visiting Nuance Communications’ website’s FAQ section. Technical and product support representatives can be reached by phone in most regions during regular business hours if you require additional assistance.
Final Words
Dragon Anywhere can accurately translate challenging and unusual words and phrases. What is even more amazing is how it gets better with time as it gets used to the unique qualities of the voice.
The features for exporting transcribed text and the voice commands are particularly helpful and a genuine delight to work with. However, I must point out that there are a few aspects of the software that could benefit from some updates, especially considering the high cost of the subscription.
Although Dragon is perhaps the most well-known transcription software in the world, the Dragon Anywhere app has significant room for improvement. Despite its high level of accuracy in speech detection, many users feel it lacks sufficient additional features.
- Dragon Professional
| Pros | Cons |
| Easy to use | Consumes computing resources |
| Precise speech recognition | expensive |
| Transcribes pre-existing audio files | Steep learning curve |
| Doesn’t work with macOS |
Speech recognition is one of the best applications of computers. These products convert spoken words into human-readable text through a microphone, saving significant effort that would otherwise be spent typing long texts and essays. Additionally, they are highly beneficial for individuals with disabilities or temporary conditions that make typing difficult.
Dragon Professional, a well-known speech recognition software, has long been owned by Nuance Communications. Nuance, originally an independent software company specializing in speech recognition and artificial intelligence products, was acquired by Microsoft in 2022.
The first version of Dragon was developed in 1997 by a company named Dragon Systems. The software has undergone numerous iterations and updates and is currently at version 16.
Dragon has remained one of the most popular and effective speech-to-text tools globally. In this review, we’ll help you determine if it’s the right tool for you to use.
Dragon Professional includes all the features of Dragon Home, along with additional customizations designed to simplify tasks for professionals.
Dragon Professional allows users to create custom words and phrases, such as proper names or specialized industry terminology, which may be frequently used in their work.
Additionally, the software offers custom functionality to facilitate working across various devices, including PC touchscreens, smartphones, and tablets.
Benefits – Do you often use the same text and graphics repeatedly? With Dragon Professional, you can create custom voice phrases to quickly insert them. The Professional edition also allows you to start working on your desktop PC and seamlessly continue on another device using the Anywhere functionality.
Documentation – In addition to memorizing words and phrases, you can set smart format rules to apply abbreviations, contact details, or dates according to corporate styling guidelines. You can highlight, underline, or bold text and adjust font sizes using voice commands. This functionality works seamlessly within common business applications.
Plans and Pricing
Dragon Professional has straightforward pricing. Each license costs a one-time fee of $699, which covers English, French, and Spanish. Discounts are available for bulk licenses through negotiations with Nuance’s sales team.
While $699 is a significant expense, it is a one-time payment, allowing you to enjoy your version of Dragon Professional indefinitely. However, if a new version is released and you wish to upgrade, an additional one-time fee of $349 is required.
Nuance also offers a cloud-based version of Dragon Professional on a subscription basis, starting at $55 per month or $660 annually.
Features
Dragon Professional is specifically designed for the Windows operating system, with the macOS version being discontinued by Nuance Communications in 2018. Mac users can instead utilize another Nuance product called Dictate for Mac.
Dragon Professional caters to both individual and enterprise users, offering numerous benefits. For instance, individuals with limited hand mobility can utilize Dragon Pro to type using voice commands. Notably, assisted living facility operators employ Dragon Pro to facilitate easy communication for residents.
The software boasts high accuracy and can comprehend words, phrases, and sentences in English, French, and Spanish. However, it could be more flawless and may occasionally require manual correction for mistakes.
Dragon Pro can transcribe live speech into text in real-time and transcribe pre-existing audio files stored on your computer. You have the option to transcribe audio files individually or in bulk using the Auto Transcribe Folder Agent (ATFA).
Nuance employs deep learning techniques to continually enhance the software’s performance, particularly as the cost of deep learning tools decreases over time.
One of the notable features of Dragon Pro is the ability to create custom voice commands for automating tasks. For instance, you can use a specific phrase to insert standard boilerplate text automatically or to add signatures to documents. Dragon Pro is interactive, allowing you to share your custom commands with other users.
Another valuable feature of Dragon Pro is its advanced vocabulary management. Often, there are industry-specific terminologies that speech recognition software doesn’t recognize by default. However, with Dragon Pro, you can add these unique words to your vocabulary. Simply speak the word clearly and specify the associated text for the software to input whenever it hears it. Once added, Dragon Pro will consistently recognize the unique word.
Dragon Professional Anywhere
Nuance offers a cloud-based alternative to Dragon Professional known as Dragon Professional Anywhere. This version allows users to access the software online from anywhere, enabling logins from any computer with the appropriate credentials. This differs from the traditional Dragon Professional, where usage is typically limited to the specific PC for which the license was purchased.
One advantage of the cloud-based version is its utilization of artificial intelligence for transcription, enhancing accuracy by continuously learning and adapting to the user’s accent. Due to the demanding computing resources required, such AI-based systems cannot be run on local PCs, but Professional Anywhere grants access to online AI resources.
Nuance claims up to 99% accuracy for Professional Anywhere without the need for voice training. Upon initial use, the platform establishes a cloud-based voice profile for the user, automating manual adjustments such as accent modifications and microphone calibration, as typically required in the local version of Dragon Professional.
Setting up and installing Dragon Professional Anywhere is straightforward compared to the local version, as complex configurations are not necessary initially. This cloud-based model operates on a subscription basis, unlike the local version, which entails a one-time payment.
Dragon Professional Anywhere is a secure tool featuring 256-bit encryption for your data, ensuring compliance with HIPAA requirements for confidentiality in medical settings.
This cloud-based version includes a unique feature called Anchor Focus Dictation, allowing you to dictate into a document while keeping your eyes on a different window. The document you’re dictating into will be displayed as a small anchor on your screen, enabling you to focus on other tasks.
For enterprise buyers, usage can be managed through the Nuance Management Center. This center allows administrators to easily track employee usage, distribute licenses based on that usage, and manage and share customizations from a centralized dashboard.
Dragon Professional is an invaluable tool, whether you use the locally-hosted app, the cloud-based version, or the mobile app. It addresses a significant challenge for individuals with disabilities who find it difficult or impossible to type long documents, allowing them to dictate words and convert them into text seamlessly.
Interface
Dragon Professional is a user-friendly tool with a simple interface that is easy to understand. However, the platform has a steep learning curve, requiring time to become familiar with all its features, especially the customization options. It is not a tool you can expect to master quickly.
For users with non-native English accents, additional time will be needed to train Dragon Professional to accurately recognize their pronunciation.
One drawback of Dragon Professional is its high consumption of random access memory (RAM). Running Dragon Professional alongside other applications can be challenging, particularly on low-end or mid-range PCs with limited processing power.
Support
Nuance Communications provides customer support via email and telephone. You can open a ticket on the official website and expect an email response within 24 hours. Additionally, you can contact the technical support line for immediate assistance with any issues.
The official Dragon Professional website also offers a range of resources, including user guides, cheat sheets, and tutorials, to help you get the most out of the software.
Final thoughts
In some respects, Dragon Professional is the app without a specific niche in the Dragon software portfolio. Dragon Home is perfect for home users, while Dragon Legal is tailored for lawyers and legal professionals. Nuance also offers specialized solutions for law enforcement, financial services, and medical professionals.
This raises the question of why someone would choose the general “professional” version when an industry-specific version with a more comprehensive feature set is available. Dragon Professional is ideal for businesses, freelancers, and even ambitious home users who need something more advanced than Dragon Home but do not require the specialized vocabulary of Dragon Legal. It offers robust documentation functionality that suits a wide range of users.
Dragon Professional is one of the best speech-to-text tools available, making life easier for individuals with limited hand use who find typing difficult or impossible. However, it does have drawbacks, such as a steep learning curve needed to become proficient with the software.
- Otter
| Pros | Cons |
| Precise real-time prescription | No live chat support |
| User-friendly interface | Can be expensive |
| Free version is available for students and casual users | It’s not useful if you don’t need text transcriptions |
| Searching keywords, timestamps, sharing and editing can be done | Minutes per conversation and month are quite limited in the free version |
| Works well on a mobile | AI is accurate but there are issues with noise interference and similar things |
| Perfect for Mac users | Some editing and cleanup is needed for longer recordings |
Otter AI is an AI-powered notetaker that automatically generates transcripts, summaries, and action items from meetings, sparing you the need for manual note-taking. It features a built-in chatbot for instant meeting-related queries and content generation. It helps organize and schedule meetings across various remote meeting platforms and provides transcriptions for future reference.
Utilizing advanced algorithms, Otter AI analyzes and interprets audio recordings in real-time, converting them into text for seamless transcription. It supports popular online conferencing platforms such as Zoom, Microsoft Teams, and Google Meet and is available on iOS and Android devices for mobile accessibility.
In addition to real-time transcription, Otter AI provides 30-second summaries for quick review of meeting highlights, along with action items to outline next steps. By automating the tedious task of taking meeting notes, Otter AI streamlines meeting efficiency and collaboration, eliminating the need for designated notetakers and manual note-taking hassles. Say goodbye to frantic scribbling during meetings!
Otter AI serves as an AI transcriber and meeting assistant, seamlessly joining your online meetings and generating notes automatically. Leveraging its advanced speech recognition technology, Otter AI asserts itself as the most precise AI transcriber available in the market. l.
Otter.ai offers flexible pricing plans and a full-featured free version. The pro version includes advanced professional features, which can also be accessed for free through a referral program.
Pros
– Most accurate AI transcriber for real-time online meetings.
– Enhance transcription accuracy by teaching Otter jargon, names, acronyms, and other specific words.
– Compatible with major video conferencing platforms like Zoom, Google Meet, and Microsoft Teams.
– Export conversations in TXT, DOCX, PDF, or SRT formats for captions or email sharing.
– Chrome Extension enables OtterPilot to join meetings instantly.
– Integrates with Slack and Dropbox.
– Otter AI app available on iOS and Android for on-the-go transcription.
– The free plan offers 300 monthly transcription minutes with a 30-minute per conversation limit.
Cons
– Transcriptions are mostly accurate but may require manual review for errors.
– Accuracy may be affected by background noise or thick accents.
– Supports only English (U.S. and U.K.) and regional accents.
– Does not record video of meetings.
Plans and Pricing
Otter offers three plans with varying tools and features. The free Basic plan is the simplest, allowing users to record up to 600 minutes of audio per month. Recorded audio can be played back, exported as text, or edited using various tools. Additionally, speaker identification is included.
A Premium subscription costs $8.33 per user per month when billed annually ($9.99 with monthly payments). It includes up to 6,000 minutes of audio recording and a range of advanced features.
Finally, the Teams subscription costs $12.50 per user per month when billed annually ($14.99 with monthly payments). It includes all features of the Premium plan plus team management tools like user statistics and centralized billing.
Features
with a wide array of features. Firstly, it allows users to record and automatically transcribe conversations using either their phone or computer. Additionally, it can recognize and distinguish between different speakers.
Otter also allows users to edit and manage transcriptions directly within the app. Audio recordings can be played back at various speeds, and images and other content can be inserted directly into the transcriptions. Additionally, users can import audio and video files for transcription.
Set up
Setting up a new Otter account is quick and easy, taking just a few minutes. To begin, simply create a free account. You can sign up using your Apple, Google, or Microsoft login, or by entering a few basic personal details to create a new account.
If you’re using Otter on your smartphone, download the app from the Google Play Store or Apple App Store. For desktop devices, simply login to your new account and start using the web interface. If you encounter any issues, a comprehensive getting started guide is available to help.
Interface
Overall, the Otter user interface is well-designed and intuitive. It features essential tools like a record button, an import button, and a log of recent activity. A quick tutorial is available on the main dashboard to help you get started with the basics.
The navigation menu on the left side of the screen grants access to past recordings and shared files. You can use the built-in search bar to locate specific conversations, and users can create and manage groups and folders.
Performance
Otter performs exceptionally well, offering quick and accurate voice-to-text transcriptions with minimal waiting time. We tested it on a laptop without a microphone or headset, and it still accurately identified different speakers with very few errors. Issues may occur when multiple people speak simultaneously, but this is expected.
Additionally, Otter’s supplementary processing tools are excellent. The program operates seamlessly, and the editing process is intuitive.
Likewise, uploading and processing existing audio and video files is straightforward. Even large files are quickly imported (subject to your internet connection, of course), allowing you to store, edit, or transcribe them from audio to text. It’s important to mention that while video files are uploaded, Otter only retains the audio portion.
Support
Regarding support, Otter exclusively provides online ticket submission. Queries are sent via the contact page, and subsequent communication is conducted through email. It’s important to note that priority support is available for paying subscribers.
Alternatively, Otter offers valuable resources through its quick start guide and FAQ section. The FAQ page addresses a variety of common questions, making it particularly helpful for new users. Similarly, the quick start guide offers clear documentation on each of the program’s features.
Final Thoughts
Otter AI stands out as the most accurate AI transcriber for online meetings, offering real-time transcription and the ability to customize vocabulary for enhanced accuracy. While its transcription quality is generally high, manual review may be necessary to correct errors, and it is limited to English. However, Otter AI’s commitment to privacy and seamless integration with popular conferencing platforms make it an invaluable tool for teams seeking productive and collaborative meetings!
Overall, it’s hard to find fault with Otter. This speech-to-text transcription app is incredibly popular, and rightfully so. Its well-designed user interface makes getting started a breeze, whether on desktop or mobile devices. Otter offers versatility, a host of premium features, and outstanding performance.
While customer support may be slow for free users, upgrading to a paid plan ensures priority assistance. In truth, Otter is an excellent option for anyone seeking a voice-to-text transcription app.
- Verbit
| Pros | Cons |
| Fast and accurate services | Multi-language support could be better |
| Extensive video captioning tools | Price determined per customer |
| Integrates with major platforms | Customization can be complex |
| Professional grade services | Complex for beginners |
| Real-time support | |
| A comprehensive suite of tools |
Verbit.ai specializes in delivering professional AI transcription and captioning solutions with a focus on high accuracy and rapid turnaround times. Its versatile platform caters to various needs, including meetings, events, podcasts, and live formats, and seamlessly integrates with popular tools such as Zoom and Microsoft Teams, enhancing its suitability for professional environments.
A standout feature of Verbit.ai is its real-time access to services, supported by a team of over 5,000 expert human transcribers. This combination of AI technology and human expertise ensures a consistently high level of accuracy and reliability. While Verbit.ai offers a comprehensive suite of tools, its pricing may be relatively higher, and some of its advanced features may require a learning curve for new users. Nevertheless, its professional-grade services and robust support system position it as a top choice for organizations in need of dependable transcription and captioning solutions.
In the transcription industry, platforms typically rely either on AI technology or human transcribers, serving primarily as tools for work distribution. Verbit stands out as it integrates both approaches. Initially, their AI software processes the audio, making its best effort to transcribe the content. Subsequently, human transcribers review and correct any errors.
This hybrid approach, leveraging over 35,000 human transcribers alongside advanced AI, offers a high likelihood of accurate transcription. However, Verbit’s strengths extend beyond this innovative methodology.
Verbit offers a comprehensive suite of transcription and captioning software and services designed to convert video and audio content into text documents quickly, accurately, and compliantly. By integrating artificial and human intelligence, Verbit serves legal professionals, academic institutions, broadcasting and media companies, and businesses, delivering industry-specific transcripts efficiently. Verbit’s services help reduce operational costs, streamline critical processes, and enhance access to and engagement with content.
Using advanced machine learning algorithms, Verbit’s tools produce transcription and captioning outputs that adhere to your specified guidelines and requirements. These AI-generated outputs are then meticulously reviewed by professional editors to ensure accuracy. Verbit also provides real-time transcription and captioning, enabling seamless transcription during meetings with immediate delivery of transcripts upon completion.
Benefits
The main benefits of Verbit include enhancing audience access and engagement with content, generating accurate transcripts and captions, and reducing operational expenses. Here are the details of each benefit:
- Content Access & Engagement
Verbit facilitates the transformation of video and audio content into text documents in real time, enhancing access and engagement for your employees, clients, or other audiences. Real-time transcription and captioning can be initiated immediately or scheduled according to your needs.
During conferences or meetings, Verbit automatically generates live captions, allowing your audience to easily consume and understand the content. This fosters active participation and engagement with both you and other presenters.
Additionally, Verbit provides immediate transcripts once the meeting concludes. These transcripts serve as comprehensive documentation of the discussion, enabling you to share them, along with the video recordings, with your audience or other relevant parties.
- Accurate Transcripts & Captions
Verbit harnesses the power of both artificial and human intelligence to deliver highly accurate transcripts and captions. Its AI-powered transcription and captioning software generate outputs that conform to your specific guidelines and requirements.
Using machine learning algorithms, Verbit’s software automatically reviews the notes you provide and integrates information from previous transcription and captioning sessions as well as external sources. The software can also learn the specific language and terminology of your industry.
Additionally, Verbit employs professional editors to review the AI-generated outputs and make necessary corrections. You can monitor the entire transcription and captioning process from start to finish, ensuring the highest accuracy and quality.
- Operational Cost Savings
Using Verbit’s software and services can significantly reduce your operational expenses. For example, in the legal industry, you can save considerable time and money by automating the preparation of legal and court transcripts. Verbit streamlines the legal transcription process, reducing the time and cost associated with generating, reviewing, and submitting these documents.
Additionally, Verbit offers collaboration features that enhance efficiency and further reduce costs. You can share the transcription and captioning software with your team members or colleagues, allowing them to work on stored files collaboratively. They can review, comment, edit, and update files within the software, speeding up processes and saving even more money.
Plans and Pricing
Verbit offers tailored speech-to-text packages designed to serve specific markets, including corporate learning, court reporting, education, and media production. Additionally, Verbit provides audio description and live transcription services.
While the underlying technology remains consistent across these packages, the key difference lies in the inclusion of captions with timestamps for some services. Captions with timestamps can be used as video subtitles, enhancing the accessibility and usability of the content.
However, the critical questions typically addressed in this section remain unanswered, as Verbit has opted for an enterprise-focused approach without a fixed cost structure.
Some companies find this approach challenging, as it makes it difficult to determine if the service offers good value compared to similar services provided to other businesses.
Verbit asserts that their pricing is ‘competitive’ compared to exclusively human transcription services, although they do not disclose specific costs. They also mention that volume users can expect discounts.
Features
The Verbit platform provides access to advanced voice recognition AI technology, accelerating transcription and delivering faster results than human-only transcription services.
When you use Verbit to transcribe audio, its AI algorithms adapt to the unique signatures of the sound file by creating acoustic, linguistic, and contextual event models. These features enable Verbit to reduce background noise, distinguish accents, and identify terms related to current news issues.
You can monitor your jobs through the Verbit Cloud portal with real-time status updates throughout the transcription process. Verbit also integrates with various third-party services, allowing you to easily distribute the transcriptions.
Set up
Submitting a transcription request to Verbit is straightforward and requires no technical expertise. To create an account, begin by contacting the Verbit team through the “Contact Us” web page. After discussing your transcription needs, Verbit will provide a rate for your job. If you accept the rate, they will proceed to set up an account for you.
To initiate a transcription, simply upload an audio file to your provided Verbit Cloud account. Verbit’s AI technology will transcribe the file, which will then undergo double-checking by two human transcribers. Once the process is finished, you can download the completed work in your preferred file format.
This process is quite straightforward and efficient.
Additionally, Verbit offers a separate live captioning service with its pricing structure and methodologies.
Interface
The Verbit interface features a clean and minimalistic design, making it user-friendly.
On the user’s home screen, there is a list of all transcription jobs along with their current status. This allows users to quickly discern which jobs are completed, awaiting oversight, or marked as ‘Inaudible’ by the human transcribers.
On this webpage, users can easily add new audio or video files. In case of any issues, there’s a convenient chat portal where support agents are available to assist.
While the interface isn’t optimized for managing large numbers of documents, it functions well for the needs of individual users.
Performance
The top-tier human transcription services boast an accuracy rate of 99%, while the most advanced AI technology we’ve evaluated typically achieves 95-98% scores.
During our testing, Verbit’s transcription accuracy approached 99% across various content types, such as public lectures and court proceedings. This level of accuracy is remarkable, especially considering that the transcription speed surpassed that of human-only services by a significant margin.
One significant factor contributing to Verbit’s high accuracy level is its use of two human transcribers as a fail-safe for errors. Recognizing that everyone can have off days, and acknowledging issues related to accents, Verbit ensures an extra layer of accuracy assurance by involving two human transcribers in addition to the AI processing.
This dual-check system significantly reduces the likelihood of major errors in transcriptions being delivered to clients.
Furthermore, Verbit offers a unique feature when captioning is included. Timestamping is generated on a per-word basis, allowing words in the caption to be highlighted as they are spoken.
Support
Enterprise customers typically expect a high level of support from the services they engage with, often considering it a crucial aspect of what they pay for.
Verbit’s reputation in this regard is exceptional, as each account is assigned a dedicated customer success manager who serves as the main point of contact. While managers may not be available 24/7, Verbit provides a fallback option with a live chat service that operates round the clock, capable of directly addressing most inquiries.
Verbit has developed a series of webinars aimed at helping users maximize the potential of their existing accounts. These webinars explore how transcription can provide commercial advantages across various industries.
Final thoughts
The unique blend of machine intelligence and human oversight is a winning combination for achieving the highest levels of transcription accuracy.
Verbit delivers exceptionally precise transcriptions and offers useful tools for movie captioning, phrase searching, and seamless content sharing through external app integrations.
However, determining whether the price of this service aligns with your business needs requires an initial discussion with Verbit. That’s the missing piece of the puzzle that you can only obtain through direct communication with them.
- Speechmatics
| Pros | Cons |
| Powerful transcription engine | No out-of-the-box solutions |
| Impressive API integration | |
| Try for free |
Speechmatics operates with the primary goal of comprehending every voice. It offers a speech-to-text API engine that can be integrated into the technology stacks of various solutions and service providers across diverse industries and use cases. Businesses worldwide rely on Speechmatics to accurately convert natural human speech into text, regardless of the speaker’s age, gender, accent, dialect, or location. With operational bases in Cambridge and London in the UK, Denver in the USA, Chennai in India, and Brno in the Czech Republic, Speechmatics is renowned for its extensive reach and advanced functionality in voice translation and transcription.
Transcription services can be categorized into those acting as intermediaries between clients and transcriptionists and those leveraging AI-based software solutions. Some companies offer both types, with a significant cost difference between human-based and AI-based services.
Speechmatics belongs to the AI-based category and prides itself on the quality of its code for converting audio to written text, even offering real-time transcription.
While many companies boast about the accuracy of their AI technology in transcribing human speech into text, Speechmatics stands out for its transparency and credibility in the performance of its code, based on our analysis.
Speechmatics offers advanced online speech recognition technology that benefits business professionals, writers, and various industries requiring efficient note-taking. This transcription technology supports keyword triggers, making it ideal for media monitoring, media asset management, and subtitling—both live and closed captions. Additionally, Speechmatics is valuable for call center training by generating text files of call recordings, which can then be utilized for quality management, compliance, dispute resolution, and training purposes. Its automatic speech recognition capabilities encompass multiple languages, including Czech, German, Italian, Korean, Polish, Spanish, and many others. Speechmatics can be deployed on-premise or via a cloud provider and is designed to scale with the growth of a business.
Benefits
- Accurate Transcriptions
With advanced speech recognition technology enhanced by machine learning, Speechmatics offers users highly accurate transcriptions. This technology can recognize and understand a wide range of languages and accents, from European languages like Polish and Spanish to Asian languages like Korean and Japanese, ensuring precise transcriptions even in non-English languages.
- Enhanced Compliance
Speechmatics delivers highly accurate transcriptions, enabling users to conduct thorough reviews of call transcripts, which leads to improved audits and compliance. These precise transcriptions also facilitate the extraction of business insights to inform future decisions. Additionally, the transcriptions are valuable for training and quality management, ensuring compliance is maintained throughout all processes.
- Versatility
Speechmatics, as a voice-to-text software, offers flexibility in deployment, whether through a cloud provider or on-site within a company’s premises, enhancing data security. Moreover, it seamlessly scales alongside businesses, thanks to its easily expandable technology.
Plans and Pricing
Speechmatics takes pride in its unique approach, notably refraining from participating in the cost-per-minute model with upfront pricing. This decision reflects Speechmatics’ focus on selling to Enterprises, where the price is determined by the scope of the agreement rather than solely by the amount of transcription performed.
Generally, the transcription cost decreases with increasing volume, and a principal Speechmatics sales team can elucidate the economics of partnering with their service. The precise pricing will depend on specific requirements, necessary tools, desired features, and anticipated transcription volume. Should circumstances shift, Speechmatics can flexibly adapt costs accordingly, customizing the solution precisely to the client’s needs.
Features
While skilled developers may find it relatively straightforward to create transcriptions for languages with common dialects, accents, and known regional vocabularies, Speechmatics operates differently. As of the time of writing, Speechmatics offers transcription services for a wide range of languages, including Arabic, Bulgarian, Cantonese, Catalan, Croatian, Czech, Danish, Dutch, English, Finnish, French, German, Greek, Hindi, Hungarian, Indonesian, Italian, Japanese, Korean, Latvian, Lithuanian, Malay, Mandarin (Traditional and Simplified), Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Slovenian, Spanish, Swedish, and Turkish.
Moreover, Speechmatics supports multiple dialects within many languages, allowing it to comprehend variations such as American, Australian, and Irish English as effectively as standard English. The transcription process can be either batch-based, creating documents from recorded audio input, or real-time, enabling live audio analysis for tasks like subtitling TV channels or streamed broadcasts.
During transcription, Speechmatics applies appropriate punctuation to the text, including full stops, commas, and other symbols. For Enterprise customers seeking complete control, Speechmatics is highly configurable. This flexibility is particularly crucial for businesses employing language specific to their sector, allowing customization of special words, meanings, interface design, and even the handling of sensitive language or taboo words.
Set up
What sets Speechmatics apart from typical transcription systems is that it doesn’t come pre-configured for immediate use. The setup process is integral to its learning model, and its complexity varies based on the customer’s intended usage.
For most users, this entails creating a customized interface that integrates with Speechmatics via its API. Subsequently, users are responsible for managing the processing and delivery of transcribed audio back to the user.
As part of its offerings, Speechmatics provides a deployment team to assist customers in determining their preferred utilization of the technology and identifying the critical components of the process.
Deployment options encompass accessing Speechmatics via their cloud platform, utilizing a public cloud, installing the system on-premises, or employing a combination of these approaches.
Interface
Somewhat disappointing is the absence of a pre-existing general-purpose interface from Speechmatics that customers can customize. Instead, companies are expected to develop in-house software solutions and integrate Speechmatics’ transcription technology into their workflows using the Speechmatics API.
This requirement presupposes a certain level of IT resources from the client and may constrain the speed at which transcription services can be implemented for those in need. To streamline and expedite this process, Speechmatics can connect customers with regional partners who offer prebuilt user interfaces and expertise in customization.
However, the effectiveness of these options hinges on the compatibility of the prebuilt interfaces with the customer’s existing systems.
Performance
Many companies boast about having powerful transcription software capable of delivering near-perfect results with just a click or command line input, but Speechmatics truly lives up to this claim.
Although testing the software isn’t straightforward, as the demo involves inputting lengthy command lines with embedded encryption keys twice, the outcomes are impressive. As part of our testing process, we utilized the opening paragraphs of the first Harry Potter book, narrated by the esteemed Stephen Fry.
Having tested numerous transcription tools, we’ve encountered every imaginable error and misinterpretation, particularly with names like ‘Dursley’s’ and ‘Dudley’. However, Speechmatics outperformed them all. Throughout the entire passage, it made only one error, referring to the company ‘Grunnings’ as ‘Runnings’.
This represents the most accurate result we’ve witnessed in this particular test, surpassing others by a significant margin.
In a more challenging test of audio quality, the AI demonstrates an impressive ability to accurately decipher words even when the speaker’s voice is muffled or distorted due to outdoor conditions. Notably, the speed at which it transcribes is remarkable, effortlessly handling a couple of minutes of audio in just a few seconds.
While we didn’t delve into these features, the option to apply a custom word dictionary to the account can further enhance speed and accuracy, resulting in swift turnarounds and transcriptions requiring minimal adjustments. Additionally, the processing engine exhibits an exceptional capability to distinguish between multiple speakers, even when they share a common accent.
Overall, Speechmatics excels in AI transcription quality, surpassing some human-created transcriptions we’ve encountered.
Final thoughts
Achieving the best solution often demands both time and financial investment, and this holds particularly true for Speechmatics.
While it doesn’t offer a conventional out-of-the-box solution, this approach ensures that users don’t expect the transcription company to resolve all workflow issues by simply throwing money at the problem.
Speechmatics stands out as one of the top speech-to-text transcription programs available. Although there’s no free trial or plan, a demo can be requested if necessary. The transcription engine itself is exceptionally powerful, delivering fast and accurate real-time and batch transcriptions.
Furthermore, Speechmatics offers a range of advanced features, such as accent recognition, the ability to customize personal dictionaries with custom words, and impressive punctuation tools.
Overall, Speechmatics presents a compelling option, particularly for larger businesses with significant transcription needs. For precise pricing details, it’s advisable to engage directly with the company’s sales team.
- Microsoft Azure Speech-to-Text
| Pros | Cons |
| Precise voice analysis that improves with custom speech models | Complicated to set up |
| Can be run locally to safeguard voice data entry |
Microsoft Speech to Text, also known as Azure Speech to Text, is a service provided by Microsoft designed to convert spoken language into written text. Utilizing automatic speech recognition (ASR), this technology transcribes audio content into text format. By leveraging advanced machine learning algorithms and artificial intelligence, Microsoft Speech to Text aims to deliver accurate transcriptions, making it valuable for a wide range of applications.
Microsoft Azure Speech to Text is among the most advanced voice-recognition platforms available. As part of Microsoft’s Cognitive Speech Services product range, it employs deep learning algorithms to handle poor sound quality and adapt to various speaking styles for accurate audio transcriptions.
It is important to note that Microsoft Azure Speech to Text is not a typical user-friendly dictation software. Instead, it is a developer-oriented platform intended to help businesses create, test, and manage their products. You may find alternative speech-to-text apps more suitable if you aim simply to transcribe a batch of audio files. Check out our Best Speech-to-Text Software guide for the top alternatives.
Features
- High Accuracy: Microsoft Speech to Text utilizes advanced speech recognition technology to provide precise transcriptions.
- Real-Time Processing: It supports real-time audio streaming, enabling live transcriptions as speech is spoken.
- Customization Options: Users can create custom language and acoustic models to enhance accuracy for specific domains or industries.
- Speaker Diarization: The service can identify and differentiate between multiple speakers in an audio stream or recording.
- Language Support: Microsoft Speech to Text supports a wide range of languages, making it suitable for global applications.
- Punctuation: It automatically adds punctuation marks to transcribed text, improving readability and comprehension.
- Profanity Filtering: The service includes built-in profanity filtering to ensure clean and appropriate transcriptions.
- Batch Processing: Microsoft Speech to Text supports batch processing for transcribing large volumes of pre-recorded audio files.
How to use
Step 1: Set Up an Azure Account
- If you don’t have an Azure account yet, sign up for one. Subscribe to the Azure Speech service to get started.
Step 2: Obtain the Subscription Key
- After creating the Speech resource in Azure, retrieve the subscription key. This key is essential for authenticating your API calls.
Step 3: Choose an SDK or API
- Decide on the programming language or API endpoint you will use to interact with the Azure Audio-to-Text service.
Step 4: Configure Audio Input
- Prepare the audio file or stream that you want to convert to text. The service supports audio formats such as WAV, MP3, and FLAC.
Step 5: Implement the Conversion
- Based on your chosen SDK or API, follow Azure’s documentation and code samples to integrate the audio-to-text conversion functionality into your application.
Applications of Azure Audio to Text
Azure Audio to Text service is designed for various use cases, including:
- Transcription services
- Content creation
- Call centers
- Accessibility needs
- Market research
- Voice assistants
- Legal and law enforcement
- Education
The service provides accurate and efficient audio-to-text conversion,
Plans and Pricing
With Microsoft Azure Speech to Text’s free plan, you can transcribe up to five hours of audio and create one custom voice model each month. However, this plan supports only one concurrent audio request at a time, making it unsuitable for most businesses.
To transcribe multiple speech clips simultaneously, you must upgrade to the standard Azure pricing plan. This plan costs $1 per hour of audio and supports up to 20 concurrent requests. Additional fees apply if you use a custom audio model or need to transcribe multichannel sound files, costing $1.40 and $2.10 per audio hour, respectively.
Although Microsoft presents its pricing in “per audio hour” terms, as is common in the industry, billing is divided into one-second increments, ensuring you only pay for the processing time you use.
Features
The primary feature of Azure Speech to Text is its access to Microsoft’s advanced natural language processing system. In recent years, Microsoft’s speech AI has achieved several significant milestones. As a result, it can now perform tasks previously impossible for a speech recognition service, such as accurately transcribing cross-talk during small group conversations.
Azure supports dozens of languages and dialects and can be customized with speech recognition models to better adapt to a user’s speaking style, background noise, and vocabulary. If your organization is already integrated with the Microsoft product ecosystem, you can leverage Office 365 data to enhance speech recognition accuracy for organization-specific terms. This can be achieved without compromising data security, as Speech Text can be run on-premises.
Set up
Microsoft Azure has been designed for developers rather than consumers. This means that setting it up is an involved and somewhat challenging procedure best left to someone with a good deal of technical know-how.
The quickest way to set up Azure is by using the Azure Speech SDK with a programming language like Java or C++. First, register for a free Azure account and create an empty project in your development environment. Then, Microsoft Visual Studio was used to write a short program that initialized Microsoft’s SpeechRecognizer object.
Interface
Similar to other bulk transcription platforms, Microsoft Azure Speech to Text is designed to be used as an application programming interface (API), integrated into Office 365 programs, or incorporated into new platforms and services. Consequently, there is no single Azure Speech-to-Text interface. The end-user experience will vary depending on how Azure Speech to Text has been implemented.
Meanwhile, the developer managing Azure will use Microsoft’s online Azure Portal, which is modern and user-friendly. It takes just a few minutes to find the speech services resource page, and once an instance is added to your account, you can view monitoring alerts and usage in a single window.
Support
To learn how to interact with the Azure Speech Services SDK through different programming languages and integrate the Azure Speech-to-Text functions into your platform, you’ll need some help. Fortunately, Microsoft has created a comprehensive catalog of training materials for the Azure platform, in which you’ll find code examples and handy tips.
Additionally, all Azure customers receive free billing and subscription management support, accessible through a ticket system. For more comprehensive support, you can add a plan to your account, starting at $29 per month.
Final Thoughts
The Azure Speech-to-Text platform makes use of cutting-edge technology to provide a near-perfect transcription service. It’s most suitable for businesses already invested in the Microsoft Office 365 ecosystem because custom voice and vocabulary models can be securely generated from your existing document archive. Some small businesses may struggle with Azure, as setting it up properly requires attention from a qualified Microsoft cloud developer.
- IBM Watson speech-to-text
| Pros | Cons |
| Fast & accurate speech recognition | More expensive than AWS or Google |
| Grammar, language and acoustic model training | Multi-speaker recognition is hit-and-miss |
Watson is IBM’s natural language processing computer system, which powers the renowned question-answering supercomputer and a range of AI-based enterprise products, including Watson Speech to Text. In our review of Watson Speech to Text, we will examine one of the top speech-to-text applications available, ideal for those looking to convert audio to text on a large scale.
The Watson speech processing platform is available on IBM Cloud. It’s a versatile tool and can be used in many contexts including dictation and conference call transcription. What’s more, unlike most other speech-to-text apps, it’s available as an API, allowing developers to embed it into voice control systems, among other things.
Plans and Pricing
With Watson Speech to Text, you can process up to 500 minutes of audio for free each month. If you exceed this limit, you’ll be charged for each additional audio minute, with rates varying based on the duration of the audio processed. Costs range from $0.01 to $0.02 per minute, and there’s an additional charge of $0.03 per minute if you require IBM’s Custom Language Model. Premium quote-only Watson plans are also offered, providing access to advanced data privacy features and uptime guarantees.
Access to the Watson Speech-to-Text system is available through a comprehensive IBM Cloud subscription, which offers a variety of AI services. Natural language processing is just one among many applications within this wide range of offerings. This makes it an excellent choice for organizations requiring access to high-speed data transfers, chatbots, or text-to-speech tools.
Features
Due to its flexible API integration and various pre-built IBM tools, the Watson speech recognition service extends beyond simple transcription tasks. For instance, if you aim to utilize it within a customer service framework, Watson Assistant can be configured to directly handle natural language questions or respond to queries via telephone.
Watson works with live audio in 11 languages and can import sounds in a variety of pre-recorded formats. When streaming, real-time diagnostic support means Watson can prompt users to move closer to their microphone or change their environment. Also impressive is the fact that Watson can distinguish between different speakers in a shared conversation thanks to Speaker Diarization, a feature still undergoing beta testing.
Setup
To begin using Watson, the initial step is to create an IBM Bluemix account, which is a straightforward and free process, only requiring an email address and password for registration. After logging in, you must provision the Speech to Text service on your account. At this stage, you’ll receive a set of credentials that should be securely saved for future reference.
Once you’ve completed the initial setup, the process becomes notably more intricate. Accessing Watson requires integrating those credentials into a set of client Uniform Resource Locator (cURL) code and executing it on your machine. To determine the precise command to use, you can refer to a helpful guide. Alternatively, if you prefer to assess the performance of the Watson system without navigating through these steps, you can explore it on IBM’s demo site instead.
Interface
In contrast to voice-to-text applications targeting consumers, Watson’s services are tailored for access through APIs and code integration within other systems. Consequently, there isn’t a conventional Watson “interface.” Instead, Watson can be accessed through three distinct internet protocols: WebSockets, REST API, and Watson Developer Cloud.
To manage Watson, you’ll utilize a command-line tool that establishes a connection to IBM’s cloud through one of those three routes. The interface that end-users interact with when using Watson will need to be independently developed by someone on your development team.
Support
To manage Watson, you’ll utilize a command-line tool that establishes a connection to IBM’s cloud through one of those three routes. The interface that end-users interact with when using Watson will need to be independently developed by someone on your development team.
If you cannot find a solution to your issue there, you can directly contact IBM by opening a support ticket or reaching out to them via phone. If you have chosen one of the premium Watson packages, your Watson usage will be safeguarded by a Service Level Uptime agreement.
Final Thoughts
Organizations equipped with the expertise and resources to effectively integrate the IBM Watson Speech-to-Text platform into their systems can enjoy advanced features such as real-time sound environment diagnostics and interim transcription results. Nevertheless, smaller businesses and organizations may find it challenging to navigate the technical complexities involved in setting up Watson properly.
- Braino Pro
| Pros | Cons |
| Precise | Looks dated |
| A flexible tool | No Mac version |
| Can transcribe pre-recorded with plugins | Recent price hike |
Many voice recognition tools employ artificial intelligence techniques to improve their accuracy, and Braina Pro does just that.
However, what sets it apart is its versatility. Unlike many others, Braina is a multi-purpose tool that can be utilized across various scenarios and applications.
Moreover, instead of relying on an AI model with a fixed understanding of human speech, it utilizes a learning algorithm. This algorithm analyzes each session to better comprehend your speech patterns.
Plans and Pricing
Where other software of this type expects a monthly subscription, Braina only has one-off payment options, and of the three possibilities, one of those is a Free ‘Lite’ release.
Braina Pro, the commercial product, can either be subscribed for a year or indefinitely with a lifetime license. A year costs $79, and a lifetime license is $199 for a single user.
This is much more than it cost a couple of years ago, when a lifetime single license cost only $139, and a yearly subscription was just $49.
For those curious, the free Lite release lacks is the ability to dictate live input, it’s exclusively English only, and it doesn’t have the learning functionality of the Pro version, among other differences.
All the desktop versions are exclusively for the Windows platform (XP or higher).
The Android release is free to everyone, but, oddly, the Apple iPhone or iPad version costs $19.99 for the privilege. In both cases, the application is merely a means to redirect captured audio to a PC running the main application.
Design
The Braina Windows tool lacks modern application styling and doesn’t feature much visual flair. It could easily be mistaken for software designed for Windows 7 or even earlier versions of the Microsoft operating system.
The interface is straightforward, consisting of a simple windowed panel with drop-down menus at the top, an input line at the bottom, and a few icons for controlling the application’s speech and listening functions.
Its primary functions are versatile and can operate independently of other running applications or systems. One of these functions is virtual assistance, similar to Siri, Alexa, Google Assistant, and Cortana. With this feature, users can interact with their PC, ask questions, launch apps, and more, akin to the capabilities of Cortana on Windows 10. Users can extensively customize this feature, including assigning it a different name and adjusting its responses.
The second mode allows you to have any text you highlight and copy from any web page or application read out loud.
Braina’s reading voice may sound more robotic compared to Alexa or Google Assistant, and it sometimes mispronounces words. However, Braina Pro is not entirely at fault here, as this voice is generated by Microsoft and only offers two options for English speakers outside the USA.
Interestingly, Braina Pro possesses a much better online voice internally, leading to the question of why it doesn’t utilize that voice for reading text aloud.
The final feature is dictation mode, which, as the name suggests, converts spoken words into text.
AI Powered Transcription
Many transcription tools support a decent number of languages and regional variations spoken in different countries. However, Braina stands out by understanding over 100 languages, including some less commonly supported ones like Zulu, Thai, Lithuanian, and Afrikaans.
The broad language coverage of Braina underscores the complexity of this solution. What surprised us most was its immediate ability to understand us without any difficulty.
To use this tool in any application or website, simply activate the microphone and instruct the software to enable ‘dictation mode.’
The only issue encountered was that Braina sometimes adds extraneous words to the document if it hears them from the microphone.
Braina boasts 99% accuracy, and based on our English testing, we’re reasonably confident that this claim is not exaggerated. Additionally, it remains unfazed by background sounds such as air conditioning or fan noise.
The final component of this setup is a free (donationware) tool known as VB-CABLE, a virtual cable solution that can switch speaker output to the microphone line.
Once patched into the system and configured, it becomes possible to play any audio or video file and have Braina transcribe the sounds it hears.
Braina’s ability to refine its model through active listening is remarkable, allowing it to rapidly enhance accuracy based on prior input.
One drawback of using this method for transcription is the lack of time coding for words or speaker identification, rendering it impractical for tasks such as creating video subtitles or requiring chronological breakdowns of spoken phrases.
This limitation is unfortunate, and Braina should consider incorporating audio file processing as a standard feature, complete with timecoding and the capability to generate formatted subtitle files.
For those interested in exploring the full range of Braina’s capabilities, engaging in basic conversations with the AI is possible. In these interactions, users can pose questions and observe how the AI adapts to the responses.
If Braina encounters a question it cannot answer, it may prompt the user to provide the information, which it then stores and can retrieve if the question is posed again.
It’s important to understand that this isn’t a universal knowledge base but rather the accumulation of specific installation knowledge, allowing Braina Pro to be customized to local contexts.
To accommodate multiple users, different profiles can be utilized to prevent overlap in the voice model data that the system generates.
Android App
Brainasoft’s decision to offer the Android app for free aligns with economic logic because, without a license for the PC version, the app would serve little purpose.
The Android app enables remote control of the computer using voice commands, a virtual mouse, and a keyboard. However, its utility is limited as users cannot view the computer screen.
To establish a connection, the local IP of the host computer must be known, which may pose challenges when away from the office or behind a firewall.
Thus, the primary value of this software lies in its ability to utilize the phone as a microphone for a PC lacking such hardware.
While the Android app may not be a standout feature of Braina Pro, it could benefit certain users.
Regarding the Apple iOS version, we did not test it, but it offers similar functionality to the Android app, albeit without being available for free download from Apple.
Final Thoughts
Braina presents an interesting juxtaposition. It offers a plethora of functionalities found in other solutions, including those inherent to Windows and Android, alongside a few remarkable features exclusive to Braina.
The standout feature is its robust AI for voice recognition, which effortlessly facilitates high-accuracy dictation with minimal effort. This makes it a practical choice for individuals needing to quickly capture numerous ideas or content without spending more time correcting mistakes than dictating.
However, this primary functionality overshadows the rest, leading to uncertainty about why Braina competes with existing personal assistants available for Windows.
With its reasonable pricing, particularly for those opting for a lifetime license, Braina is accessible. Yet, notable limitations include its exclusive compatibility with Windows or Android, excluding Mac and Linux users, and its reliance on an internet connection for operation. These factors might diminish its appeal to journalists or others who require offline functionality.
Despite its legacy styling, Braina outperforms many solutions with exorbitant monthly subscription costs or pay-per-minute transcription services. Nonetheless, a recent significant price increase and indications of potential further hikes have tarnished its value proposition compared to its previous affordability.
- Amazon Transcribe
| Pros | Cons |
| It is a versatile automatic speech recognition tool. | The software works well but only allows selecting a pre-loaded vocabulary, which is a limitation. |
| Transcribes audio files in common formats like MP3. | |
| Adds timestamps to each word for easy text search and sound location. | |
| Allows personalized and expanded vocabulary for precise transcriptions. | |
| Detects speaker changes and transcribes each speaker separately. | |
| Processes audio and videos with different channels for each speaker without issues. |
Amazon Transcribe utilizes a deep learning process known as automatic speech recognition (ASR) to swiftly and accurately convert speech to text. It can be employed to transcribe customer service calls, automate closed captioning and subtitling, and generate metadata. Its features include easy-to-read transcriptions, streaming transcription, timestamp generation, custom vocabulary, vocabulary filtering, multiple speaker recognition, channel identification, and automatic content redaction. The service enhances customer service by offering insights for future decisions and supports content producers and media distributors in reaching foreign audiences. A free tier is available for prospective clients to try before purchasing, with the lowest price offered by quote. Various pricing rates can be obtained by contacting the vendor.
Benefits
The main benefits of Amazon Transcribe include enhanced customer service, improved captioning and subtitling workflows, and efficient cataloging of audio archives.
- Improved Customer Service
Amazon Transcribe helps clients enhance their customer service by converting audio input to text, enabling the development of applications that analyze texts for searching and analyzing voice input. This is particularly beneficial for the customer contact center industry, where transcribing calls and mining the resulting data can provide valuable insights.
- Captioning and Subtitling Workflows
Beyond customer service, Amazon Transcribe supports content producers and media distributors by facilitating the real-time display of subtitles with timestamps. This allows for the integration of time-stamped subtitles with video content, and when combined with Amazon Translate, it enables the creation of localized videos for foreign audiences.
- Cataloging Audio Archives
Amazon Transcribe is also advantageous for clients looking to transcribe their audio and video assets into searchable archives for monitoring and risk management. Once audio is converted to text, clients can use Amazon Elasticsearch to index and search their entire library effectively.
Cons
- Inaccurate Transcription
- Poor Transcription Accuracy
- Text Recognition Issues
Pricing
With Amazon Transcribe, you pay based on the number of audio seconds transcribed each month. It’s easy to begin with the Amazon Transcribe Free Tier: upon signup, you can analyze up to 60 minutes of audio per month for free during the first 12 months.
- Free tier
60 minutes per month for 12 months
As part of the AWS Free Tier, you can start using Amazon Transcribe for free. The Free Tier offers 60 minutes of transcription per month for 12 months from the date of your first transcription request. Usage is calculated monthly across all AWS Regions and automatically applied to your bill; unused minutes do not roll over to the next month. Restrictions apply; see offer terms for details. After your free usage period ends or if your usage exceeds the free tier, you will pay the standard pay-as-you-go rates.
- Standard Pricing
The Amazon Transcribe API for both streaming and batch transcriptions is billed monthly based on tiered pricing, which varies by region.
Audio data often contains separate channels for each speaker, such as a two-person conversation with each speaker recorded on a different channel. The rates cover up to two channels per audio stream or file. For a two-channel conversation, you only pay for the total audio duration, not separately for each channel.
Automatic Content Redaction add-on pricing
You can opt to redact sensitive information, such as personally identifiable information (PII), using Automatic Content Redaction for your transcription needs. Additional charges for this feature are billed monthly based on tiered pricing, which varies by region. Usage is billed in one-second increments, with a minimum charge of 15 seconds per request. Note that the free tier does not apply to automatic content redaction.
Custom Language Model add-on pricing
You can create Custom Language Models (CLM) by training Amazon Transcribe’s standard models with your domain-specific text. Once you have a CLM, you can select which transcription jobs will use it. Additional CLM charges apply only to the transcription jobs that utilize a custom language model. Transcriptions using your CLM are billed monthly based on tiered pricing, with usage billed in one-second increments and a minimum charge of 15 seconds per request. The free tier does not apply to custom language models.
Toxicity Detection pricing
Amazon Transcribe operates on a pay-as-you-go model, where you’re charged solely for the seconds of audio transcribed each month. Charges are calculated in one-second intervals, with a minimum per-request charge of 15 seconds. Additionally, billing occurs monthly according to the tiered pricing displayed below.
Pricing for Asia Pacific Mumbai
Standard Batch
| Tier | Volume (minutes/month) | Standard Batch Transcription ($/minute) |
| T1 | First 250,000 minutes | $0.02400 |
| T2 | Next 750,000 minutes | $0.01500 |
| T3 | Over 1,000,000 minutes | $0.01080 |
- Happy Scribe
| Pros | Cons |
| Precision | No live transcription |
| Huge language selection | |
| Money saving | |
| Automatic punctuation | |
| Multiple speaker identification |
Founded in Dublin, the small team at Happy Scribe comes from diverse backgrounds, including the United States, Spain, Ireland, and France, and the business emerged only recently.
Despite its recent inception, the service has garnered a stellar reputation among journalists, podcasters, and researchers, who depend on its accuracy in transcribing audio into text.
Plans and Pricing
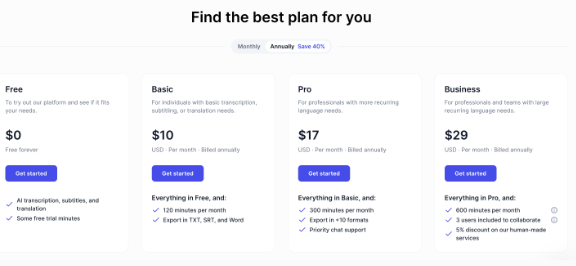
Happy Scribe offers flexible pricing models to cater to different needs:
- Pay-as-you-go: This option is ideal for occasional transcription needs. You simply purchase minutes and they are charged at a per-minute rate.
- Subscriptions: Subscriptions offer a set amount of transcription minutes per month at a recurring cost. There are various tiers available to accommodate different usage levels.
Value for the Price
Happy Scribe’s value proposition is contingent upon your requirements. Here’s a breakdown to help you decide:
- Best for occasional use: Pay-as-you-go may be the most cost-effective.
- Best for regular transcription: Subscriptions can offer better value in the long run.
- Best for high accuracy needs: Happy Scribe’s human-made option, while more expensive, is competitively priced for its guaranteed accuracy.
Design
Users familiar with transcription tools will find Happy Scribe’s process familiar: upload audio files and receive notifications when processing is complete.
What sets Happy Scribe apart is its remarkably short processing time, often completing in less than half the audio’s duration, with an hour of audio typically processed within 20 minutes.
However, speed is only beneficial if the resulting text is usable. Unlike other services where additional features often incur extra costs, Happy Scribe includes multiple speaker identification, timecoding, personalized vocabulary, and automatic punctuation as standard.
After processing, the audio can be reviewed in Happy Scribe’s transcript editor, which highlights questionable sections. Once any errors are corrected, the text can be downloaded in various file formats, including subtitle files.
Looking beyond individual or group users, Happy Scribe offers a published API, allowing external systems to integrate its technology to improve workflows or ensure accurate transcription of audio communication for record-keeping purposes.
Recordings
The online editor provided by Happy Scribe stands out as one of the best solutions for reviewing transcriptions. By default, it highlights words that the system isn’t entirely confident about. What’s intriguing is that unlike other systems, where unhighlighted words are often incorrect, this is rarely the case here.
Reviewing suspect words is relatively straightforward. Users can listen to the audio section, make necessary changes, and ensure the document’s accuracy. Once finalized, the document can be shared, exported in various formats, or converted into subtitles.
Happy Scribe’s subtitle creation feature goes beyond simple export in SRT format. It offers a complete sub-editor where users can adjust timecodes and customize how words appear on the screen.
In beta, there is currently an additional feature that translates the transcription into another language. Although it supports only ten languages at this time, this feature could be incredibly useful for those requiring subtitles in different languages.
Accuracy
While reviewing various transcription tools, the team encountered some disappointing attempts at converting high-quality audio into text. Fortunately, Happy Scribe was not one of those products.
It excelled in processing the test files, demonstrating almost perfect accuracy on some content and minimal issues even with more challenging recordings. The tests included both USA and British accents, and Happy Scribe handled both exceptionally well. While its accuracy with other languages couldn’t be confirmed, it outperformed any other transcription service for English.
Good results were anticipated with precise and clean recordings such as audiobooks, but Happy Scribe also performed admirably with live outdoor speeches that other systems struggled with. For instance, it successfully transcribed MLK’s speech from the Lincoln Memorial with only a few mistakes, despite the less-than-optimal sound quality.
For those seeking fast and affordable transcription services, Happy Scribe is recommended as the first choice. If it doesn’t meet the needs, the only alternative may be the costly option of manual transcription by native speakers.
Security
Happy Scribe asserts that its solution is fully compliant with GDPR. All data exchanged between customers and Happy Scribe is encrypted using industry-standard TLS 1.2 protocol. Additionally, the company employs advanced DDoS protection measures and implements network-level security monitoring and protection.
For whom is Happy Scribe best?
Happy Scribe’s versatile features and accuracy make it a strong fit for several use cases:
- Content Creators: Easily repurpose interviews, podcasts, or videos into blog posts, social media content, or scripts. Subtitle generation makes videos accessible to a wider audience.
- Students: Transcribe lectures or study group recordings for improved note-taking and revision.
- Meeting Transcription: Turn meeting discussions into easily searchable text records, improving collaboration and information access.
- Researchers: Analyze interviews and focus group transcripts with greater ease and efficiency.
Situations Where Happy Scribe Might Not Be the Ideal Fit
- Ultra-low budget: If cost is the primary concern, some basic transcription tools offer cheaper (though possibly less accurate) services.
- Highly specialized vocabulary: If your audio is filled with extremely niche industry jargon or scientific terms, a transcription service specifically tailored to that field might be a better choice, despite likely costing more.
- Real-time transcription: Happy Scribe doesn’t offer real-time, live transcription as some niche tools do.
Final Thoughts
Overall, Happy Scribe is a reliable and user-friendly transcription service that offers a strong balance of features, accuracy, and affordability. Its automatic transcription is impressively effective for the price, and tools like the interactive editor and subtitle generation are significant advantages. While it may not be the perfect solution for every scenario, it is a highly versatile service that meets many needs.
According to regular users, Happy Scribe proves to be a reliable solution for converting audio from 119 different languages into text. While its accuracy may vary across languages, most users express high satisfaction with its performance. Happy Scribe outperformed other transcription services and even surpassed some locally installable apps with voice training. Moreover, it offers significant cost-effectiveness compared to manual transcription, which can be time-consuming and expensive. However, it’s worth noting that Happy Scribe doesn’t provide live transcription. Nonetheless, with its strong economic justification and accurate transcription capabilities, Happy Scribe has the potential to become the preferred tool for regular conversion needs.
Happy Scribe is worth considering if you frequently need to transcribe audio or video and prioritize ease of use and value. However, if your audio often includes heavy background noise, uses highly specialized vocabulary, or requires live transcription, you should explore more specialized alternatives.
The best way to determine if Happy Scribe is right for you is to try it out. Take advantage of their free trial to test your audio and see if the results and workflow meet your expectations.
Free
- Speech notes
| Pros | Cons |
| Free Functionality | Doesn’t record for free. |
| Works on Chrome and Android | Lacks output format |
| Limited security |
What is Speech Notes?
Speechnotes is a web-based speech-to-text tool designed to boost productivity without requiring any downloads or installations. It’s an ideal solution for those who find typing challenging, whether due to a physical condition, unfamiliarity with the keyboard, or the desire to avoid strain from long hours of typing. Speechnotes is also beneficial for transcribers who can dictate recordings directly into the microphone and quickly receive written transcripts.
The platform is user-friendly, featuring a clean design that minimizes distractions and allows for a seamless flow of ideas. It uses advanced speech-recognition technology to deliver accurate results and includes features like voice commands for punctuation and easy export options to streamline your work. Additionally, Speechnotes prioritizes privacy, ensuring that your transcriptions remain secure and confidential.
Speechnotes Review: A Game-Changer for Efficient Transcription
Speechnotes has proven itself as a transformative tool for those who find typing tedious or challenging. It’s not just for those with physical typing difficulties; it’s also a boon for professionals like authors, students, and anyone needing efficient conversion of spoken words into text. The tool operates seamlessly within Chrome or Edge browsers, eliminating the need for hefty installations or high-end hardware, and is accessible on PCs, laptops, and Chromebooks, though it may be less reliable on mobile devices.
Usability and Features
Speechnotes excel in simplicity and ease of use. No account creation or login is necessary, allowing users to start immediately. The auto-save feature is particularly valuable, ensuring that no progress is lost. Additionally, the tool offers convenient options to export to Google Drive or download documents directly to your computer. However, the absence of a login system means you can’t access your documents from other computers unless they have been exported, which might be a minor inconvenience for some users.
Performance and Accuracy
The tool boasts over 90% accuracy for clear dictation or recordings, powered by Google and Microsoft’s speech recognition AI engines. The transcription process is swift, providing results in minutes—a stark contrast to the days it might take a human transcriber. Furthermore, Speechnotes is commendable for its privacy measures, ensuring that no human ever accesses your recordings.
Pricing
Speechnotes offers a straightforward and affordable pricing model. At $1.9 per month, billed annually, it’s a highly cost-effective solution without hidden fees or automatic renewals. This fixed pricing ensures users maintain control over their subscriptions, and the promise of a full refund if unsatisfied adds a layer of trust.
Limitations
While Speechnotes performs exceptionally well with high-quality recordings, it may struggle with lower-quality audio where a human transcriber might do better. The tool offers speaker diarization, but it may not be as adept at distinguishing and tagging speakers in recordings with multiple participants, such as interviews or group discussions.
Premium Features
The premium plan unlocks additional functionalities, including continuous dictation, commercial use, and direct support and feature requests from the development team. This plan is linked to your account, allowing use on multiple machines. For workflow integration, Speechnotes offers an API, webhooks, and Zapier integration, making it a versatile option for automating transcription tasks.
Community and Support
Speechnotes provide various channels for users to communicate, share issues, and request features. Premium users receive guaranteed responses from the developers, a significant advantage for those who heavily rely on the tool.
Conclusion
Speechnotes is a robust and secure transcription solution that delivers excellent value. It’s designed to be user-friendly, accurate, and private, making it an excellent choice for anyone looking to streamline their dictation and transcription tasks. While it may not be perfect for every scenario, its benefits in terms of price, privacy, and efficiency make it a compelling option for many users. If you need regular transcription services, Speechnotes is worth considering, especially with its affordable pricing and reliable performance.
Pricing
Speech notes offer basic functionality for free, allowing users to utilize its features without any cost.
Speechnotes is an AI-powered application that converts spoken language into written text, ideal for users who prefer dictation over typing or need to transcribe audio and video content. The app provides a variety of features to meet diverse user needs, with several pricing plans to suit both casual and professional users. Below is a comprehensive overview of the pricing plans available for Speechnotes.
- Dictation Free Plan
For users seeking a cost-free voice-to-text conversion solution, Speechnotes offers a Dictation Free Plan. This plan includes:
Online dictation notepad: A basic digital notepad that captures spoken words and converts them into text in real time.
Voice typing Chrome extension: An extension for the Chrome browser that enables voice typing capabilities on the web.
The free plan is ideal for users with occasional dictation needs and those who want to test the app’s core functionalities without any financial commitment.
- Dictation Premium Plan
For individuals seeking advanced features and an ad-free experience, Speechnotes offers the Dictation Premium Plan at $1.9 per month, billed annually at $22.8. This plan includes:
Premium online dictation notepad: An enhanced version of the notepad with additional features for a more robust dictation experience.
Premium voice typing Chrome extension: An upgraded extension providing a premium voice typing experience on the Chrome browser.
Support from the development team: Access to customer support for assistance with any issues or questions regarding the app.
No ads: An uninterrupted, ad-free user experience.
The premium plan is designed for users who frequently rely on dictation for their work or personal tasks and prefer a more streamlined and supported experience.
- Transcription plan
Speechnotes also caters to users who need transcription services for audio and video recordings with its Transcription Plan, a pay-as-you-go option priced at $0.1 per minute of transcription. This plan includes:
Audio & video recordings: Transcription of both audio and video files, allowing for a wide range of content to be converted into text.
Speaker diarization in English: Identification and separation of different speakers within the audio, particularly useful for transcribing interviews or meetings.
Timestamps: Inclusion of timestamps in the transcription to help users locate specific parts of the audio or video in the text.
Generate captions (.srt files): Creation of subtitle files that can be used for captioning videos.
REST API, webhooks & Zapier integration: Integration options for developers and users to automate workflows and connect Speechnotes with other apps and services.
Support from the development team: Access to customer support for any transcription-related inquiries or assistance.
The Transcription Plan is ideal for professionals needing accurate transcriptions of recordings with the flexibility of a pay-per-use model, eliminating the need for a subscription.
In summary, Speechnotes offers a range of pricing options to suit different user requirements. From a basic free plan for occasional dictation to a premium subscription for frequent use, and a flexible transcription service charged by the minute, users can choose the plan that best fits their needs, with access to customer support and additional features based on the chosen plan.
- Just Press Record
Open Planet Software’s Just Press Record is a voice recognition program made exclusively for Apple users. Convenient features like one-tap recording, transcription, and smooth iCloud syncing are available with this user-friendly software. It ensures accessibility and synchronization across various Apple platforms and is compatible with Mac computers, iOS devices (iPhone and iPad), and Apple Watch.
Pricing
Customers who are interested in obtaining Just Press Record can download the application from the Apple Store for $4.99.
Pros: Simple, modern, and user-friendly.
Cons: The organization tools need improvement.
In summary, this tool is excellent and appropriate for various users and processes. Offers a simple and easy-to-use UI system
- Dictation. Io
Digital Inspiration created the free online dictation tool Dictation.io. By utilizing speech recognition technology, Dictation.io allows users to create emails, documents, and campaigns without having to type. It does this instantly by converting audio to text.
Pros: Simple and fast solution. Understands and transcribes multiple popular languages.
Cons: Not compatible with iPhone or iPad.
In summary, Dictation. Io is a free software that translates audio into text in real-time is clear and simple to use.
- Speechtexter
| Pros | Cons |
| Swift speech-to-text conversion | Accuracy is dependent on accent and background noise |
| Supports multiple languages | It takes some time to voice commands |
| Real-time transcription for immediate results | Offline mode has less functionality than online mode |
| Simplifies text execution through voice commands | Advanced features may need to be learned |
| Customizable settings for various transcription requirements |
Speechtexter is a web-based speech recognition tool that does not require any installation. It is as easy as speaking into the program to translate spoken words into real-time text. This makes turning your speech into instantaneous text incredibly simple. You should not have any problems as long as you have an internet connection.
Since the accuracy of coverage varies by language, select one that is well-supported by Google Speech Recognition for optimal results.
A free and open-source speech recognition software, SpeechTexter provides powerful continuous speech recognition and translation features. It can generate notes, emails, and blogs on demand.
Ease of use
The simplicity of SpeechTexter is one of its best features. Its user-friendly layout is so intuitive that even beginners can easily navigate it. Just click on the microphone icon in the toolbar to start speaking to use the tool. Your voice will be transcribed into text in real-time. To make SpeechTexter even more user-friendly, a variety of keyboard shortcuts are available to control the program’s features.
Accuracy
With an astounding accuracy rate of up to 95%, SpeechTexter is among the best in its field. However, it is crucial to remember that the accuracy of the tool can change based on things like the user’s accent, diction, and background noise.
Privacy and Security
SpeechTexter encrypts all data transmitted through the application using SSL/TLS technology because it values user privacy and security. Furthermore, the tool guarantees the privacy of your personal information by not storing any user data on its servers. All things considered, SpeechTexter is a dependable and trustworthy app that you can use with assurance.
Customer Support
SpeechTexter’s website features an extensive Frequently Asked Questions section that answers a wide range of frequent questions and problems. For more individualized support, users can reach out to the SpeechTexter team directly through email or social media.
Final Thoughts
Anyone who wants to learn a new language can use SpeechTexter. It is very user-friendly and extremely accurate at identifying speech. Its extensive language compatibility makes it a vital tool that can greatly improve your language-learning process. Furthermore, its smooth integration with PolyglotClub.com offers additional benefits, particularly for individuals involved in the language-learning community.
- Podcastle.ai
Podcastle is a user-friendly and cost-effective platform for creating podcasts. It offers advanced tools for those with more complex content creation needs, but its user-friendly interface also makes it suitable for beginners.
The platform, which is powered by adaptive AI technology, is very user-friendly and allows users to quickly create podcasts even if they have no prior experience. It offers a great deal of control over project editing and refinement right within the software.
A monthly subscription fee is required to access more sophisticated tools, but this is well worth it if you plan to regularly produce podcasts and appreciate Podcastle’s simple and intuitive interface.
Pros: Podcastle boasts a user-friendly interface, a simple design, and beginner-friendly functionality in addition to its advanced features.
Cons: The AI-driven creation process might not be appropriate for seasoned podcasters looking for more control over their production, and the full feature set that is accessible through a monthly subscription can be expensive.
Detailed Review
Podcastle is an AI-enhanced recording tool designed to assist both beginner and experienced podcasters in recording, editing, and creating podcast content. It is an easy-to-use yet highly capable platform with significant potential.
Audio Recording
The first step in making a podcast is recording your audio, which is an important step even though it is not as complicated as recording music. Podcastle provides an intuitive audio recording interface that is simple to use for all users.
You have the option of recording both audio and video when you begin a new recording project. You can start making your podcast by setting up your recording project automatically with a few clicks. Simply hit the red record button to start and let the show begin. With this easy-to-use method, you can record using just your laptop.
Audio Editing
After recording your audio, the next step is editing. Podcastle provides easy access to the waveform of your recording, allowing you to click the edit function directly from the main recording window.
The audio editing window is intuitive, especially for those familiar with other audio editors. You get a basic view of the waveform, and clipping, sliding, or replacing parts of the track is simple with your mouse or trackpad. Additionally, you can drag and drop new tracks or audio files into the project, enhancing the platform’s beginner-friendly nature.
A variety of buttons and help features are available to guide you through any unfamiliar aspects. This setup is essentially an introduction to audio editing, offering basic functionality without in-depth waveform parameters. For more detailed editing, you might prefer to export your tracks to another DAW. However, Podcastle’s editing tools work well and are effective for most needs.
AI Enhancements
Now let’s explore the AI enhancements of Podcastle, which set it apart from other basic podcasting tools. The platform offers various AI tools to assist in recording, editing, and producing high-quality podcasts.
One notable feature is the ability to create an AI version of your voice or use AI-generated voices for your content. This can save time by allowing you to quickly produce a podcast from written text without needing to record it yourself.
Another great feature is the Audiobook Recording Studio, which simplifies the recording process by setting up the session for you, making it ideal for beginners.
Additionally, Podcastle offers numerous AI video editing tools. This feature is particularly beneficial for those more experienced in audio editing than video, as it helps piece together projects even if you lack extensive video editing skills.
Transcription
Transcription is another standout feature of Podcastle, enhancing the platform’s appeal. It offers a range of transcription functions that streamline and refine the podcast creation process.
Podcastle supports various audio and video file formats for transcription. Simply upload your files, and the platform will transcribe them into text, which can also be converted into your AI-generated voice or another AI voice.
The available transcription tools include MP3-to-text, audio-to-text, voice-to-text, audio translation, podcast transcription, and filler word detection. These features alone make the free basic version worthwhile, even if you don’t create podcasts.
While the transcription features are effective, they are not flawless. As with any transcription or AI tool, it’s important to double-check the output for mistakes and typos to ensure accuracy.
Final Thoughts
Podcastle is an excellent choice for anyone starting with basic podcast production. It offers all the necessary tools and features, along with AI-powered assistance, to help you create a polished podcast without needing extensive audio engineering skills.
While the basic version of Podcastle is sufficient for most beginners, full-time podcasters and content creators will need a monthly subscription to access additional features.
- Google Cloud Speech-to-Text
One of the best services for turning spoken words into written text is Google Cloud Speech-to-Text. This tool, which uses Google’s AI expertise, offers accurate and dependable speech recognition in more than 125 languages and dialects. It offers smooth integration of speech transcription services into a variety of applications and is made for both professionals and individuals. This makes it a flexible tool for anyone wishing to add voice recognition functionality to their software.
Key Features:
- Advanced Speech AI: To ensure better recognition and transcription accuracy, Google Cloud Speech-to-Text makes use of Chirp, a foundation model trained on a large amount of audio and text data.
- Global Language Support: It supports transcription for more than 125 languages and caters to a global user base that values inclusivity and accessibility.
- Live Streaming Recognition: This function is perfect for real-time applications like live captioning and customer support since it delivers transcription results instantly.
- Customizable Models: This feature is especially helpful for domain-specific applications, as users can tailor recognition models to prioritize particular words or phrases.
- Secure and Compliant: The tool complies with security and regulatory requirements, giving enterprise users confidence regarding the security of their data.
Pros
- Accuracy and Reliability: Provides outstanding precision in noisy settings or with accents.
- Ease of Integration: Adding speech recognition to any app or service is made simple by simple APIs.
- Real-Time Results: Provides immediate transcription, which is crucial for applications that require live feedback.
- Scalability: Effectively meets the needs of both small and large businesses.
Cons
- Complex Customizations: There is a steep learning curve when it comes to customizing models, which can be difficult for people who are not familiar with machine learning.
- Cost at Scale: Expenses can mount up for large-scale applications, necessitating cautious budgetary control.
- Internet Dependency: One drawback of cloud processing may be the requirement for a dependable internet connection.
Who uses Google Cloud Speech-to-Text?
- Call Centers: Using the tool for live transcription of customer service calls.
- Content Creators: Creating subtitles for videos to improve accessibility.
- Healthcare Professionals: Simplifying medical record-keeping through dictation and documentation.
- Educators: Using the tool for live captioning and enhancing student engagement in classrooms.
- Uncommon Use Cases: Adopted by podcasters for automatic transcription of episodes; utilized by researchers for transcribing field interviews.
What makes Google Cloud Speech-to-Text stand out?
With its sophisticated AI model, Chirp, Google Cloud Speech-to-Text establishes a new standard in speech recognition technology. It is crucial for developers and companies aiming for worldwide accessibility and impact because it provides real-time transcription in a variety of languages and dialects.
Compatibilities and Integrations
- Google Cloud Platform: Integrates smoothly with other Google Cloud services to enhance functionality.
- Multi-Device Compatibility: Supports voice transcription across mobile, desktop, and IoT devices.
- Custom Model Adaptation: Enables precise customization and adaptation of models to meet specific use-case requirements.
- Data Privacy: Provides encryption and compliance features designed to meet enterprise-level security standards.
Support
You can find a range of tutorials on the Google Cloud website, from quickstart guides to comprehensive instructions on incorporating the API into your apps.
Final Thoughts
For developers and businesses looking for precise and adaptable transcription solutions, Google Cloud Speech-to-Text stands out as a leading provider of cutting-edge speech recognition technology. It excels at accurately identifying a broad variety of languages and accents thanks to its unique feature, Chirp. For applications requiring real-time processing, content production, or secure transcription, Google Cloud Speech-to-Text provides stable and dependable performance.



